⇅
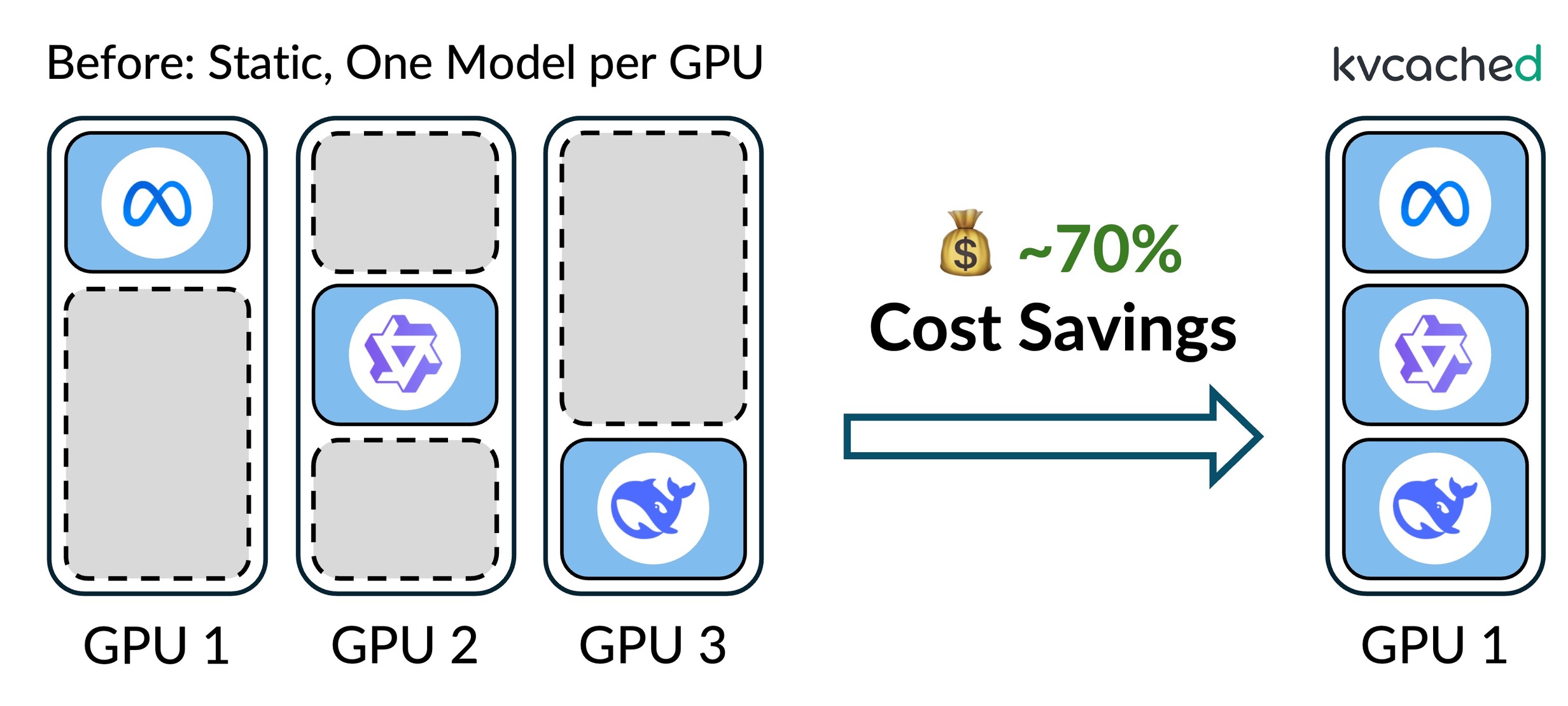
Elastic KV cache
Allocate and reclaim KV memory dynamically to match live request load.
☰
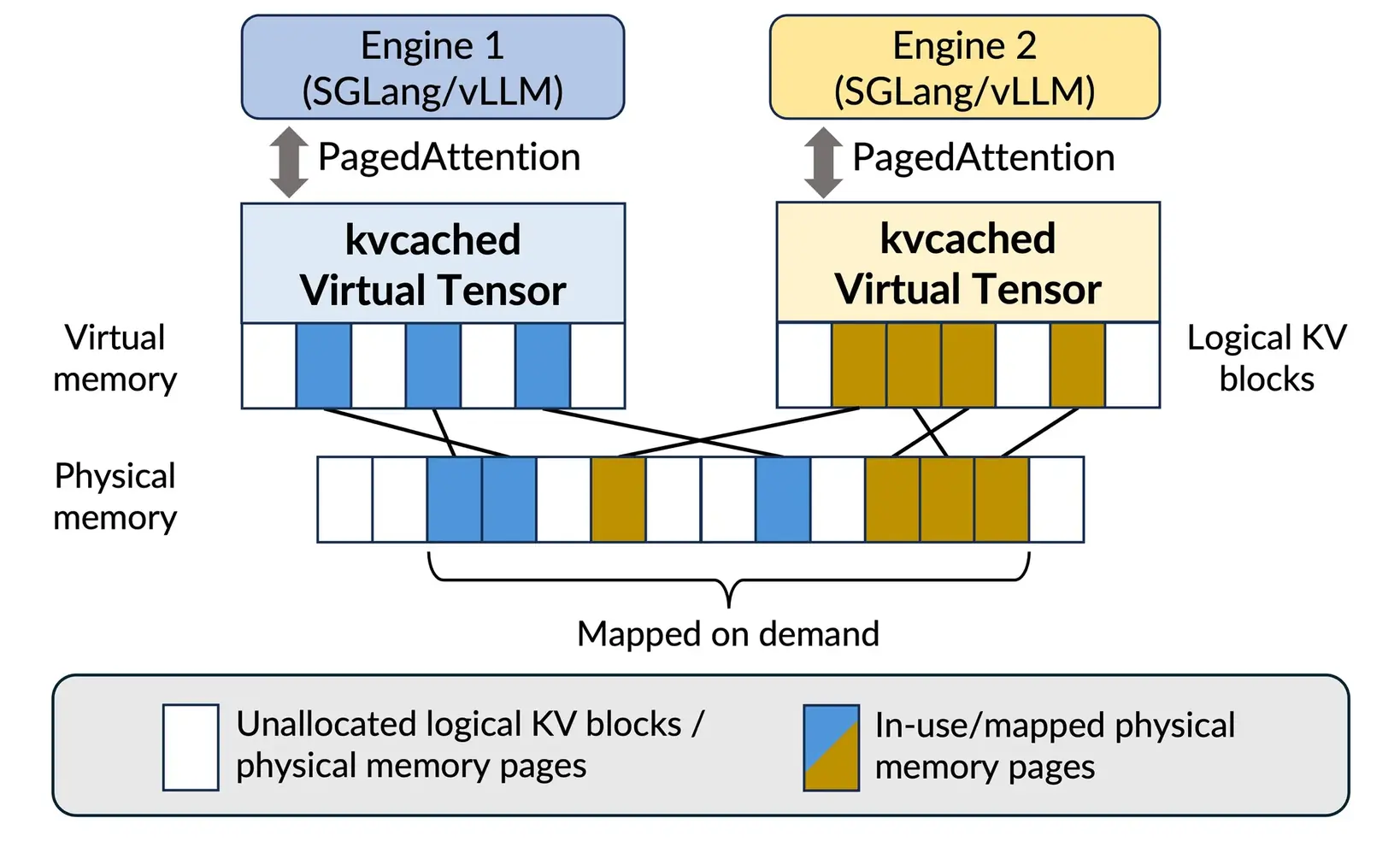
GPU virtual memory
Decouple logical KV from physical GPU memory via runtime mapping.
⚙
Memory control CLI
Enforce memory limits and manage allocation with kvcached CLI.
⬡
Frontend router and sleep mode
Route requests to the target models and put models to sleep when idle.
⚡
Mainstream serving engines
Integrate with SGLang and vLLM. No engine changes needed.
📦
Prefix caching
Support automatic prefix caching (APC) with a configurable memory bound.
 · Apache 2.0
· Apache 2.0